最近,噢,不对是好久没写博客了,但是我写了超级多笔记,比如:热修复+插件化 约2w字 面试等1w字,额额,还有论文。。。
然后最近又有些新概念,恰好被我给消费了,消费了怎么说呢,花钱了总得去学下吧,了解了解也好啊,就像大数据、区块链、微服务架构。。。。
确实是搞太多了。。。。唉,不过还好没毕业 我还可以随心所欲的安排自己的事情,这是件开心的事。
正题:环境条件
centos7的mini版
hadoop-2.5.0-cdh5.3.6.tar.gz
jdk-8u162-linux-x64.tar.gz
环境部署
安装完成后,无法联网参照:
1. 打开终端输入cd /etc/sysconfig/network-scripts/,输入ls查看网卡配置文件名,每台机器的网卡名并不相同。(我改的是ifcfg-eth0) 2. 先取得root权限,再输入vi + 网卡名回车后按i进入编辑,将最后一行的ONBOOT=no改为ONBOOT=yes,最后输入:wq! 保存并退出(sudo vi ifcfg-eth0) 3. 最后输入service network restart,重启一下。
查看下系统环境:
cat /etc/redhat-release
安装openssh
yum install openssh-server
安装后使用ssh连接,使用ip addr查看ip,回车输入密码即可登录
ssh lckiss@10.211.55.8
然后可以在外部进行操作,无需安装vm tools或者其他比如parallels tools
设置下hostname
hostname -b hadoop
修改hosts的主机名
vi /etc/hosts
卸载CentOS7-x64自带的OpenJDK并安装Sun的JDK7的方法
rpm -qa | grep java rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.7.b09.el5(根据结果修改)
Hadoop伪分布式部署
本地模式:使用本地存储,不使用HDFS
完全分布式:多台机器搭建集群环境(真实线上环境HDFS)
伪分布式:单节点模拟集群环境(虚拟机模拟HDFS)—— 这篇文章的内容
Hadoop伪分布式部署环境搭建
切换到目录
cd /opt/
查看当前目录的文件 一般是空的 如果刚刚安装
ls
防止影响环境 删除当前目录下的一切文件 执行后opt下为空
sudo rm -rf ./*
创建相应文件
sudo mkdir soft sudo mkdir datas sudo mkdir tools sudo mkdir modules
上传相关文件:( 如果上传失败 你可以考虑用root账户 或者 sudo chown -R lckiss:lckiss /opt )
新开终端切换到你存放jdk与hadoop的文件 lckiss是用户名 ip为虚拟机ip 冒号后为上传到xx目录
scp jdk-8u162-linux-x64.tar.gz lckiss@10.211.55.8:/opt/soft scp hadoop-2.5.0-cdh5.3.6.tar.gz lckiss@10.211.55.8:/opt/soft
切换ssh到虚拟机的终端
cd /opt/soft/
释放jdk与hadoop 即将java和hadoop解压到opt/modules
tar -zxvf jdk-8u162-linux-x64.tar.gz -C /opt/modules/ tar -zxvf hadoop-2.5.0-cdh5.3.6.tar.gz -C /opt/modules/
配置java环境变量
sudo vi /etc/profile
加入:
export JAVA_HOME=/opt/modules/jdk1.8.0_162 export PATH=$PATH:$JAVA_HOME/bin
使配置生效(注意退出当前session)
source /etc/profile
测试(#后面代表执行代码 再后面是输出的结果):
#echo $JAVA_HOME /opt/modules/jdk1.8.0_162
退出后重新连接ss,即可看到熟悉的东西
#java -version java version "1.8.0_162" Java(TM) SE Runtime Environment (build 1.8.0_162-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
接下来
cd /opt/modules/
给modules下的hadoop改个名
mv hadoop-2.5.0-cdh5.3.6/ hadoop/
删除hadoop的doc目录(释放空间)
sudo rm -rf /opt/modules/hadoop/share/doc/
查看磁盘空间
df -lh
切换到hadoop目录
cd /opt/modules/hadoop
查看hadoop环境
./bin/hadoop
给hadoop配置java的路径
第一个配置文件:
vi etc/hadoop/hadoop-env.sh
修改:
# The java implementation to use. export JAVA_HOME=/opt/modules/jdk1.8.0_162
第二个配置文件:
vi etc/hadoop/yarn-env.sh
修改:
# some Java parameters export JAVA_HOME=/opt/modules/jdk1.8.0_162
第三个配置文件:
vi etc/hadoop/mapred-env.sh
修改(这里本来是注释了的):
export JAVA_HOME=/opt/modules/jdk1.8.0_162
两个需要修改的XML配置文件
修改配置文件 NameNode:
#vi etc/hadoop/core-site.xml <configuration> <!-- 默认的文件访问入口 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:8020</value> </property> <!-- 临时文件目录入口 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoop/data/tmp</value> </property> </configuration>
修改配置文件 DataNode:
#vi etc/hadoop/hdfs-site.xml <configuration> <property> <!-- 默认的副本数量为1 你可以加大—> <name>dfs.replication</name> <value>1</value> </property> </configuration>
从节点名:因为是模拟 现在用的是单节点模式,所以从节点应该与主节点相同(已从配置中去除,忽略)
修改slaves 此处默认为localhost 与上面默认的文件访问入口相同 按需修改
vi etc/hadoop/slaves
以上主从节点配置完后:
退回主目录:
cd /opt/modules/hadoop/
格式化HDFS的元数据:(格式化只能进行一次 多次会引起问题 一定要格式化则需要删除data目录)
bin/hdfs namenode -format
注意查看初始化镜像文件 ls后会有data目录
cd data/tmp/dfs/name/current
ls 你会看到生成的元数据
接下来启动下namenode与datanode
sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode
查看进程
[lckiss@hadoop hadoop]$ jps 12417 Jps 12344 DataNode 12266 NameNode
接下来看管理的网址:
因为上面配置的是localhost,所以我们访问时需要使用ip来访问,当然你可以配置hosts来使用自定义的域名访问
http://10.211.55.8:50070/
查看hdfs文件系统
http://10.211.55.8:50070/explorer.html#/
无法访问?见文章底部的注意事项
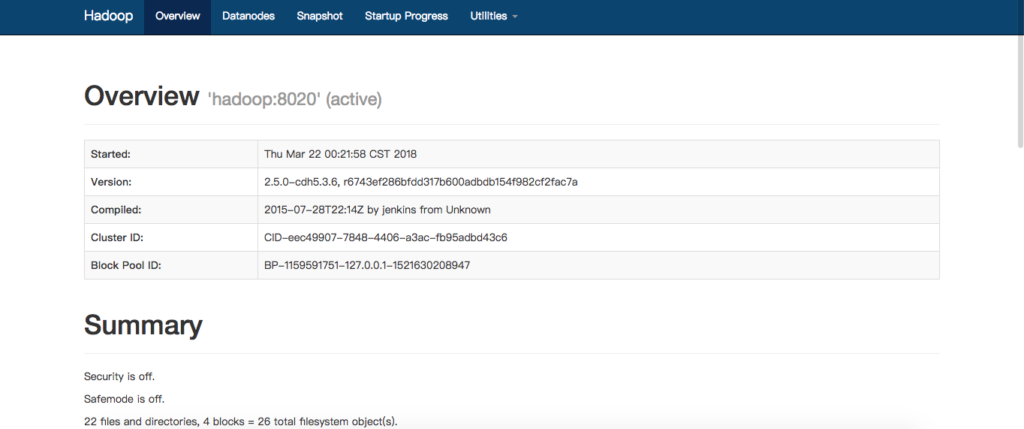
HDFS文件系统的使用
进入hadoop主目录
cd /opt/modules/hadoop/
创建个文件夹吧
bin/hdfs dfs -mkdir -p /lckiss
回车后网页那边刷新下 就可以看到了 这个地方如果不加/ 比如这样
bin/hdfs dfs -mkdir -p lckiss
这个目录会创建在/user/你的用户名/lckiss
上传呢?其实bin/hdfs dfs就会显示很多命令提示
bin/hdfs dfs -put /etc/hosts /lckiss
我们这里将系统的hosts文件上传到lckiss目录
读取,回车后就会显示文件了
bin/hdfs dfs -text /lckiss/hosts
下载到/home/lckiss下 ls /home/lckiss/ 就可以看到
bin/hdfs dfs -get /lckiss/hosts /home/lckiss
PS:一些说明
#ls data/tmp/dfs/name/current/ edits_inprogress_0000000000000000001 namenode没启动时的文件操作记录 fsimage_0000000000000000000 namenode启动后读取该文件 fsimage_0000000000000000000.md5 VERSION seen_txid
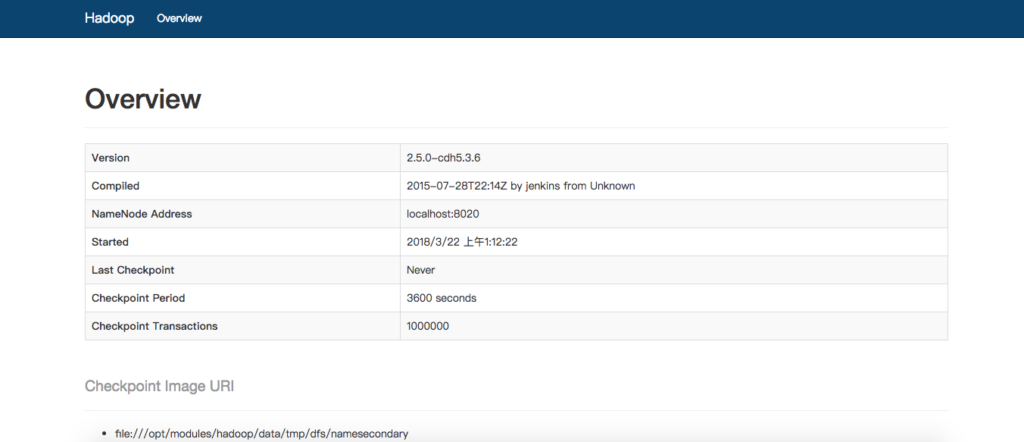
Secondary namenode机器位置交互端口号配置
修改配置文件 DataNode:
# vi etc/hadoop/hdfs-site.xml <configuration> <property> <!-- 默认的副本数量为1 你可以加大—> <name>dfs.replication</name> <value>1</value> </property> <property> <!-- Secondary namenode机器位置交互端口号 —> <name>dfs.namenode.secondary.http-address</name> <value>0.0.0.0:50090</value> </property> </configuration>
启动下
sbin/hadoop-daemon.sh start secondarynamenode
检验下进程 jps
[lckiss@hadoop hadoop]$ jps 12992 Jps 12949 SecondaryNameNode 12344 DataNode 12266 NameNode
外部访问下
http://10.211.55.8:50090/
因为Secondary namenode无法防止数据丢失,所以后面会用框架代替,这里只用于尝试使用,关闭如下
sbin/hadoop-daemon.sh stop secondarynamenode
Yarn与mapreduce配置
1. 修改 mapred-site.xml
先更名:
mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
再修改:
# vi etc/hadoop/mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
目的是:让mapreduce运行在yarn上
1. 修改 yran-site.xml
# vi etc/hadoop/yarn-site.xml <!-- 运行mapreduce的一个服务 --> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
配置完成后启动下resourcemanager与nodemanager:
sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager
附上:关闭命令
sbin/yarn-daemon.sh stop resourcemanager sbin/yarn-daemon.sh stop nodemanager
Jsp查看下
[lckiss@hadoop hadoop]$ jps 12344 DataNode 12266 NameNode 13307 ResourceManager 13579 NodeManager 13693 Jps
这样就配置完成了
外部访问:
http://10.211.55.8:8088/
如果不能访问,参考以下:
启动yarn(需要先执行过./sbin/start-dfs.sh)
./sbin/start-yarn.sh # 启动YARN ./sbin/mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况
执行下任务 小试身手
创建一个文件夹:
bin/hdfs dfs -mkdir -p /mapreduce/input
创建一个文件:
vi /opt/modules/file.input
内容为:
By default, Hadoop is configured to run in a non-distributed mode, as a single Java process. This is useful for debugging. The following example copies the unpacked conf directory to use as input and then finds and displays every match of the given regular expression. Output is written to the given output directory.
上传到hdfs中:
bin/hdfs dfs -put /opt/modules/file.input /mapreduce/input
统计单词的准备工作做完了,运行下(所有执行的都需要用jar,hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar这个是官方提供的例子,wordcount任务名称,后面分别为输入输出命令,输出目录不需要手动创建,如果已经存在output会报错,为了保护数据防止覆盖):
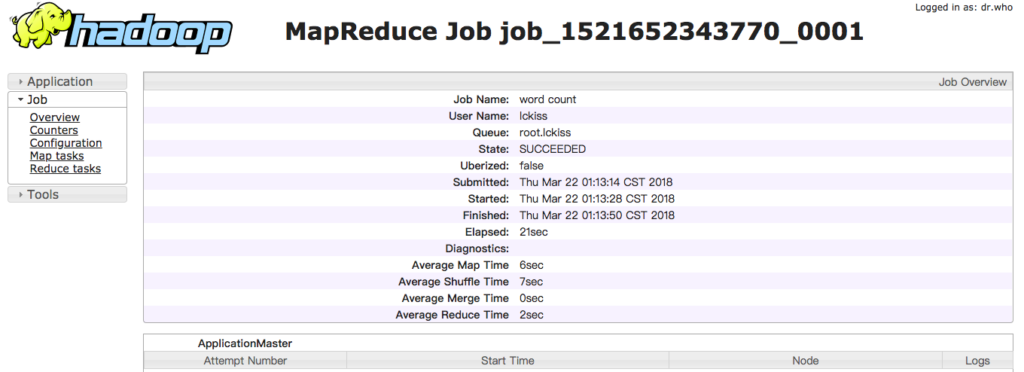
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /mapreduce/input/ /mapreduce/output
外部页面会有显示
[application_1521623193266_0001] | lckiss | word count | MAPREDUCE | root.lckiss | Wed Mar 21 17:22:04 +0800 2018 | Wed Mar 21 17:23:02 +0800 2018 | FINISHED | SUCCEEDED | | [History]
然后会在/mapreduce/output下生成两个文件夹
Permission Owner Group Size Replication Block Size Name -rw-r--r-- lckiss supergroup 0 B 1 128 MB _SUCCESS -rw-r--r-- lckiss supergroup 351 B 1 128 MB part-r-00000
_SUCCESS 说明成功了 part-r-00000是结果
我们看下结果,这样就表示成功了:
bin/hdfs dfs -text /mapreduce/output/part-r-00000
Java 1 …..

开启历史纪录管理
进入Yarn的管理网站 你会发现那个Histor是无法点击的
这里需要配置下
# vi etc/hadoop/mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>0.0.0.0:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>0.0.0.0:19888</value> </property> </configuration>
启动下:
./sbin/mr-jobhistory-daemon.sh start historyserver
现在就可以访问历史纪录了。
开启logs日志聚集服务
#vi etc/hadoop/yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 日志开启 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志存活时间 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
重启所有服务后,你就可以在历史页面点击logs了

这里有篇文章不错:
http://blog.csdn.net/qq_26937525/article/details/54616395
添加native-lib
这个需要进行编译,网上有但是不一定适用,用法是
解压到/opt/moduels/hadoop/lib中即可,解压后路径为/opt/moduels/hadoop/lib/native
一些注意的事
无法访问?关防火墙
sudo systemctl stop firewalld.service
关闭selinux
sudo vi /etc/sysconfig/selinux
修改为
SELINUX=disabled
HDFS操作错误
如果报错类似如下(因为你或许不是用的localhost)
mkdir: Call From hadoop.localdomain/10.211.55.8 to hadoop:8020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
需要sudo vi /etc/hosts
将hadoop 添加到127.0.0.1与::1后面
元数据错误
可能会出现 There are 0 datanode(s) running and no node(s) are excluded in this operation. 解决方案:找到hadoop安装目录下 hadoop/data/dfs/data里面的current文件夹删除 重新格式化元数据 启动Hadoop
常用操作
开启集群:
sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode sbin/yarn-daemon.sh start nodemanager sbin/yarn-daemon.sh start resourcemanager
关闭集群:
sbin/hadoop-daemon.sh stop namenode sbin/hadoop-daemon.sh stop datanode sbin/yarn-daemon.sh stop nodemanager sbin/yarn-daemon.sh stop resourcemanager
开启关闭dfs与yarn
sbin/start-dfs.sh sbin/stop-dfs.sh sbin/start-yarn.sh sbin/stop-yarn.sh
历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver sbin/mr-jobhistory-daemon.sh stop historyserver
删除测试用的目录
bin/hdfs dfs -rm -R /mapreduce/output bin/hdfs dfs -rm -R /tmp
字符统计
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /mapreduce/input/ /mapreduce/output
结语:
慢慢折腾,官方文档也是可以看的~
本站由以下主机服务商提供服务支持:
0条评论