本文基于:Hugo Doks v0.3.3
之前在选择静态文档框架时找到了 Doks,但其搜索有问题,而且使用的人少,相关文章基本为 0 就搁置了,今天有空尝试解决了搜索问题,想来可以用起来了。看效果:
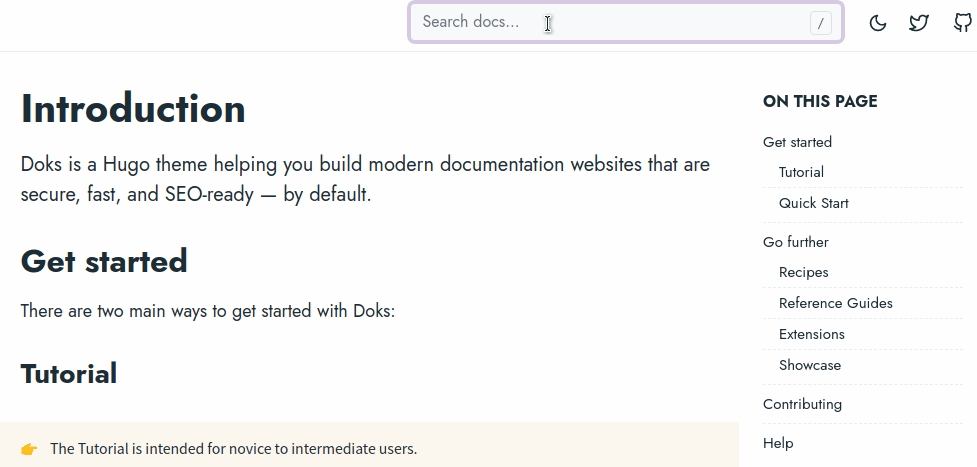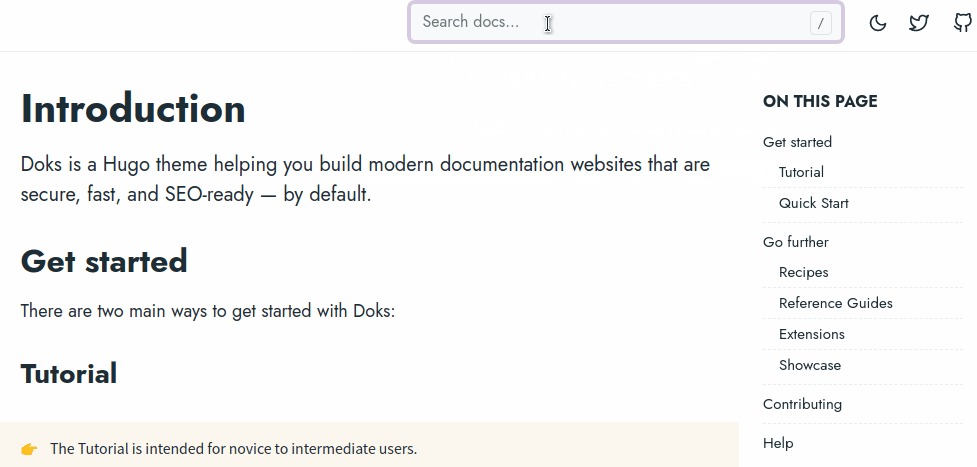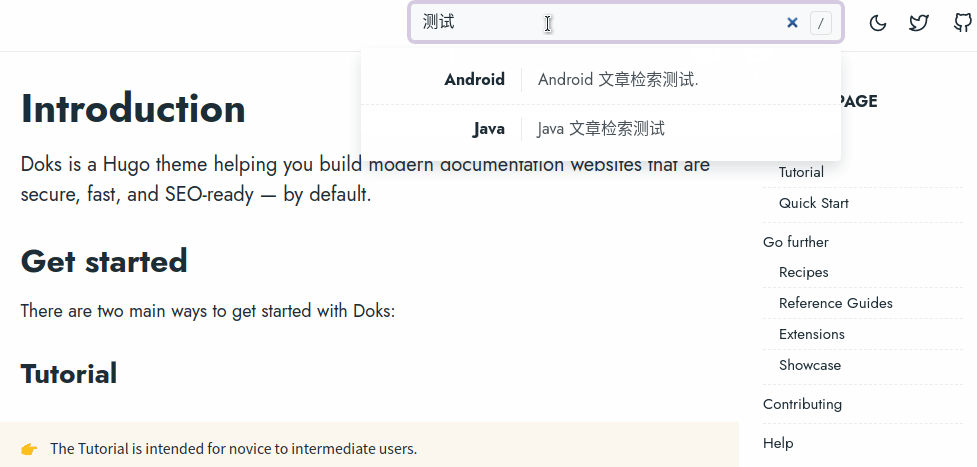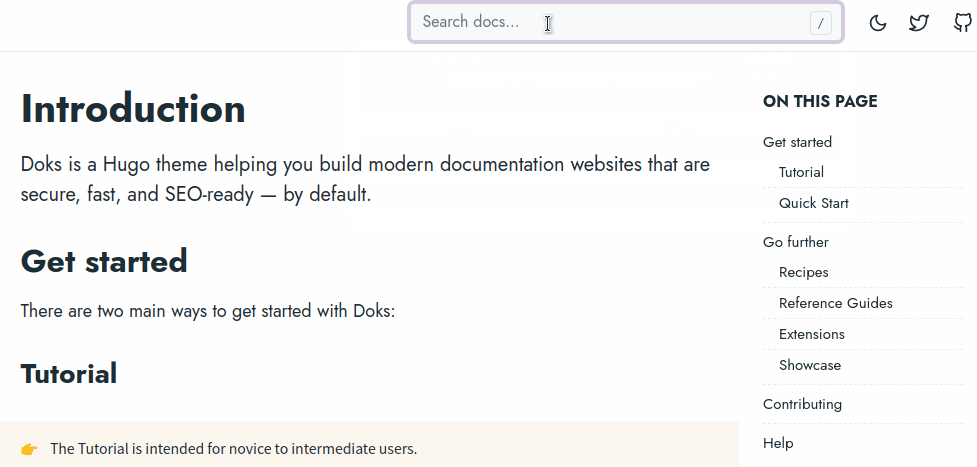
这里中文支持主要是三个问题:
1. 配置 Flexsearch,使搜索框架支持中文分词。
2. 修正 Doks 搜索功能结果显示错误问题。
3. 注释代码块导致的 js 文件加载出错
对于 Doks 的 child theme 是无法进行配置的,至少我没能找到相关配置文件,所以我直接使用的完整版。配置文件路径在:assets/js/index.js
对于第一个问题需要修改 FlexSearch 初始化的代码块:
var index = new FlexSearch.Document({
cache: 100,
document: {
id: 'id',
store: [
"href", "title", "description"
],
index: ["title", "description", "content"]
},
// Insert language specific settings below — e.g. Latin
encode: str => str.split("")
});这是修改后的代码,改动主要在追加了一行 encode: str => str.split("") (这里和官方不一样,官方的使用后将只支持中文,因为replace是将非中文替换为空串),同时删除了一行:tokenize: "forward", 可自行对比原文件。
对于第二个问题:这个原因在于显示结果时,只用了最外层循环导致结果显示不全,同时对于搜索结果的清除存在逻辑错误。主要函数为 index.js 中的 show_results() ,直接整块替换即可(这里检索的内容包括了title、description、以及content,可自行从数组中移除不需要进行检索的):
function show_results() {
var value = this.value;
var results = index.search(value, { limit: 5, index: ["title","content","description"], enrich: true });
var entry, childs = suggestions.childNodes;
suggestions.classList.remove("d-none");
suggestions.innerHTML = "";
results.forEach(function (res) {
res.result.forEach(function (result) {
entry = document.createElement("div");
entry.innerHTML = "<a href><span></span><span></span></a>";
(a = entry.querySelector("a")),
(t = entry.querySelector("span:first-child")),
(d = entry.querySelector("span:nth-child(2)"));
console.log(results);
a.href = result.doc.href;
t.textContent = result.doc.title;
d.textContent = result.doc.description;
suggestions.appendChild(entry);
});
});
}对于第三个问题,我表示很意外,一个开源项目,居然没人发现这个问题,直接删除中间那段注释代码即可:
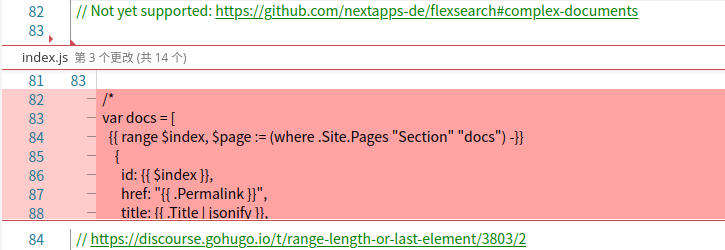
其他部分未做修改。
此外关于 Flexsearch 的配置项,可通过右键直接查看部署后的 index.js 会看到其内容与以下代码相关:
这里举例说明一下:
document: {
id: 'id',
store: [
"href", "title", "description"
],
index: ["title", "description"]
// index: ["title", "description", "content"]
},可以看到,这里我注释了对于 content 字段的检索,那么在用的时候也就得由之前的
var results = index.search(value, { limit: 5, index: ["content"], enrich: true }); 改为:
var results = index.search(value, { limit: 5, index: ["description"], enrich: true });此时将主要由 description 字段进行检索匹配,以上。
参考:
本站广告由 Google AdSense 提供
21211221
encode: str => str.split(“”)这个也不是支持中文啊,不是整词搜索,相当于把汉字拆分成一个一个字符去匹配输入的内容
Mosaic-C
新版已经废弃了,之前的那些做得也不好。似乎在文档上有了新的解释,直接看末尾的链接按指引操作。